前言
在介绍 GraphQL 之前,先讲一个故事:
前端同学: 你给我返回的接口里面客户列表全是 ID,能不能返回详细信息
后端同学: 你自己根据 ID 去调用客户详情接口好了
前端同学: 目前接口能带上客户详情吗
后端同学: 不能
后端同学: (卒)
实际开发中我们常常遇到这种情况,前后端常常因为接口字段,类型等等问题进行友好的交流。前端总是想一次性拿到所有的数据,避免多次请求,尤其是带有先后顺序的请求;后端不想跨不同数据源获取数据,希望保持每个数据源为独立的接口便于维护。
而 GraphQL 的出现就是为了解决以上问题。
什么是 GraphQL
GraphQL 既是一种用于 API 的查询语言也是一个满足你数据查询的运行时。 GraphQL 对你的 API 中的数据提供了一套易于理解的完整描述,使得客户端能够准确地获得它需要的数据,而且没有任何冗余,也让 API 更容易地随着时间推移而演进,还能用于构建强大的开发者工具。
它具有以下优点:
- 在前端准确描述想要的数据,不多也不少
- 获取多个资源只用一个请求,GraphQL 查询不仅能够获得资源的属性,还能沿着资源间引用进一步查询
- 类型系统保证了数据正确
现阶段的困难
虽然 GraphQL对于前端有很多价值,但是提供 GraphQL API 的工作量却在后端。
如何解决?
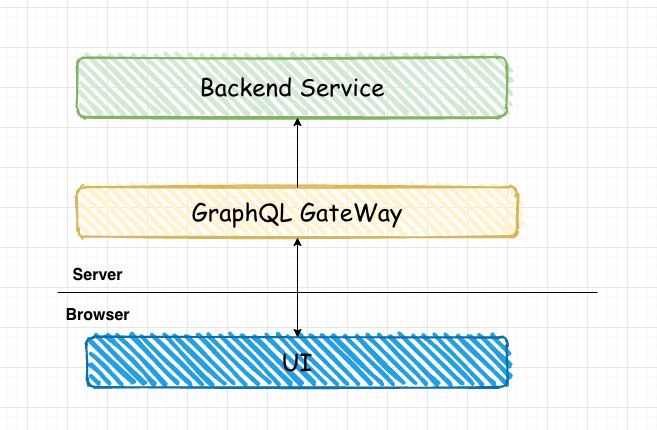
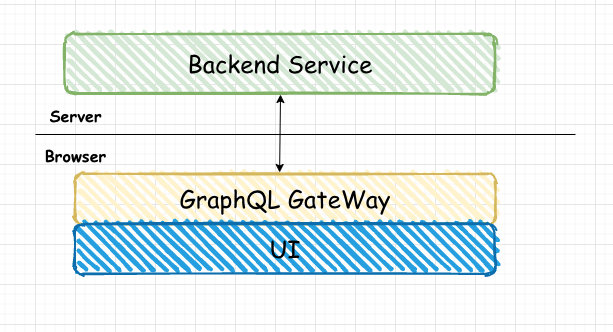
实际上,GraphQL 并不限制你运行的地方,我们完全可以把 GraphQL 网关层放在浏览器中。这样我们不需要后端配合,也可以等成熟后快速转换为后端服务。
实战
GraphQL网关
假设我们有两个接口,分别为获取订单列表接口和获取客户详情接口。
现在我们把它们转换为GraphQL。
首先我们需要定义GraphQL类型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| # schema.graphqls
# get /orders 返回 [Order]
type Order {
id: Int
# 客户ID
customerId: Int
}
# get /customers/{id} 返回 Customer
type Customer {
id: Int
name: String
code: String
}
type Query {
order(page: Int, pageSize: Int): [Order]
customer(id: Int): Customer
}
|
然后我们定义GraphQL的schema
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
import { makeExecutableSchema } from "@graphql-tools/schema";
import typeDefs from './schema.graphqls'
const resolvers = {
Query: {
async order(obj: any, args: any, ctx: any, info: any) {
const res = await fetch(`/orders?page=${args.page}&pageSize=${args.pageSize}`).then(res => res.json);
return res;
},
async customer(obj: any, args: any, ctx: any, info: any) {
const res = await fetch(`/customer/${args.id}`).then(res => res.json);
return res;
},
}
};
export default makeExecutableSchema({
typeDefs: typeDefs,
resolvers,
});
|
对这一步,和在nodejs上建立GraphQL的schema一模一样。然后我们需要将schema暴露出去。然后我们需要将schema暴露出去。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
var express = require('express');
var { graphqlHTTP } = require('express-graphql');
var { buildSchema } = require('graphql');
var schema = buildSchema(`
type Query {
hello: String
}
`);
var root = {
hello: () => {
return 'Hello world!';
},
};
var app = express();
app.use('/graphql', graphqlHTTP({
schema: schema,
rootValue: root,
graphiql: true,
}));
app.listen(4000);
console.log('Running a GraphQL API server at http://localhost:4000/graphql');
|
1
2
3
4
5
6
7
8
9
10
|
import schema from "./schema";
import { graphql } from "graphql";
export const graphqlClient = {
async query(source: string) {
const result = await graphql({ schema, source });
return result;
},
};
|
1
2
3
4
5
6
7
8
|
graphqlClient.query(
`query getOrder{
order(page: 1, pageSize: 20) {
id,
customerId
}
}`)
|
扩展订单类型
我们知道GraphQL的优点之一就是将多个请求合并成一个请求,并且可以通过资源的字段属性进一步查询。
我们将在Order上添加Customer类型,以获取订单对应的客户名称。
1
2
3
4
5
| # schema.graphqls
...
extend type Order {
customer: Customer
}
|
1
2
3
4
5
6
7
8
9
10
11
12
|
const resolvers = {
Query: {
...
Order: {
async customer: (order: any) {
const res = await fetch(`/customer/${order.customerId}`).then(res => res.json);
return res;
}
}
}
};
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
graphqlClient.query(
`query getOrder{
order(page: 1, pageSize: 20) {
id,
customerId,
customer {
id
name
}
}
}`)
|
n+1问题
当我们执行一次订单查询的时候,会返回20个order,然后我们需要在调用20次客户查询接口,总计调用了 20+1次。
我们知道GraphqlQL会沿着链路依次查询,order->customer->xxx,如果链路很长,会导致GraphQL响应变慢。
目前GraphQL通用的解决方案是Facebook提供的Dataloader, 他的核心思想是Batch Query和Cached。
假设我们有一个接口,可以通过id列表查询所有的客户/customers?id=123,456,789
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
import DataLoader from "dataloader";
import keyBy from "lodash/fp/keyBy"
async function batchGetCustomers(keys: string[]) {
const result = await fetch("/customers?id=" + keys.join(",")).then(res => res.json());
const resultMap = keyBy("id", result);
return keys.map((x) => resultMap[x] || null);
}
const customerLoader = new DataLoader(batchGetCustomers);
const resolvers = {
Query: {
...
Order: {
async customer: (order: any) {
return customerLoader.load(order.customerId)
}
}
}
};
|
最终我们把查询从20+1次降低到1+1次
总结
虽然我们解决了复杂数据的组织问题,但是难以避免会产生各种性能问题。在以后的计划里,我们将更进一步:
- 使用独立后端提供GraphQL网关服务
- 使用持久层解决数据缓存问题
- 使用低代码实现任意数据的组织